GPT4.5 and AI at the Frontier
Published on: Mar 04, 2025Filed under: Technology
Last Thursday evening, OpenAI released their latest model GPT4.5. This new model was not greeted with the calls to stop training for six months so the world could prepare [1]. It wasn’t met with hyperbolic articles claiming it will solve nearly-every problem including that very specific business case that you have. It wasn’t met with much of anything, really.
Why is that?
To put it bluntly, autoregressive models like GPT are encountering the Neural Scaling Wall and attempts to get more juice from them is seeing diminishing returns.
Training and Inference
First, a qualifier. There’s two important steps in any machine learning model, from a modest linear regression to a 670B parameter LLM: training and inference.
Let’s over simplify, shall we?
Before you can use a model, you need to train it. Looking only at neural networks, this step involves creating layers and layers of nodes (colloquially the hidden layers) with random values and then an output layer and pushing training data through the network to get the wrong answer. The network then adjusts the weights and biases of the nodes and their connections to improve those outputs.
For small neural networks this can take seconds to hours to days. For the larger neural networks like GPT4.5, this takes months. [+]This is one of the breakthroughs with DeepSeek, the team was able to reduce the time it takes to train using commercial-grade hardware
Once the model is trained, the final weights and biases are exported and loaded onto servers, hooked up to an API and can be accessed. This [+]dramatic oversimplification pretrained model is what ChatGPT uses to produce outputs. We call that interaction inference.
The Levers and the Wall
To increase the capabilities of an LLM, we have 3 levers we can pull:
- We can increase the amount of data we train with.
- We can increase the size of the neural network.
- We can increase the compute power to train and infer faster.
The issue is those levers are not improving LLMs with the dramatic improvements we saw between GPT2 and GPT-3, or even GPT-3 and GPT-3.5 [+]When it comes to GPT models, whole number versions typically suggest new, bigger models while half number versions typically suggest improvements to inference speed.
This is due to two things.
First, the levers are practically maxed. [3][4][5]
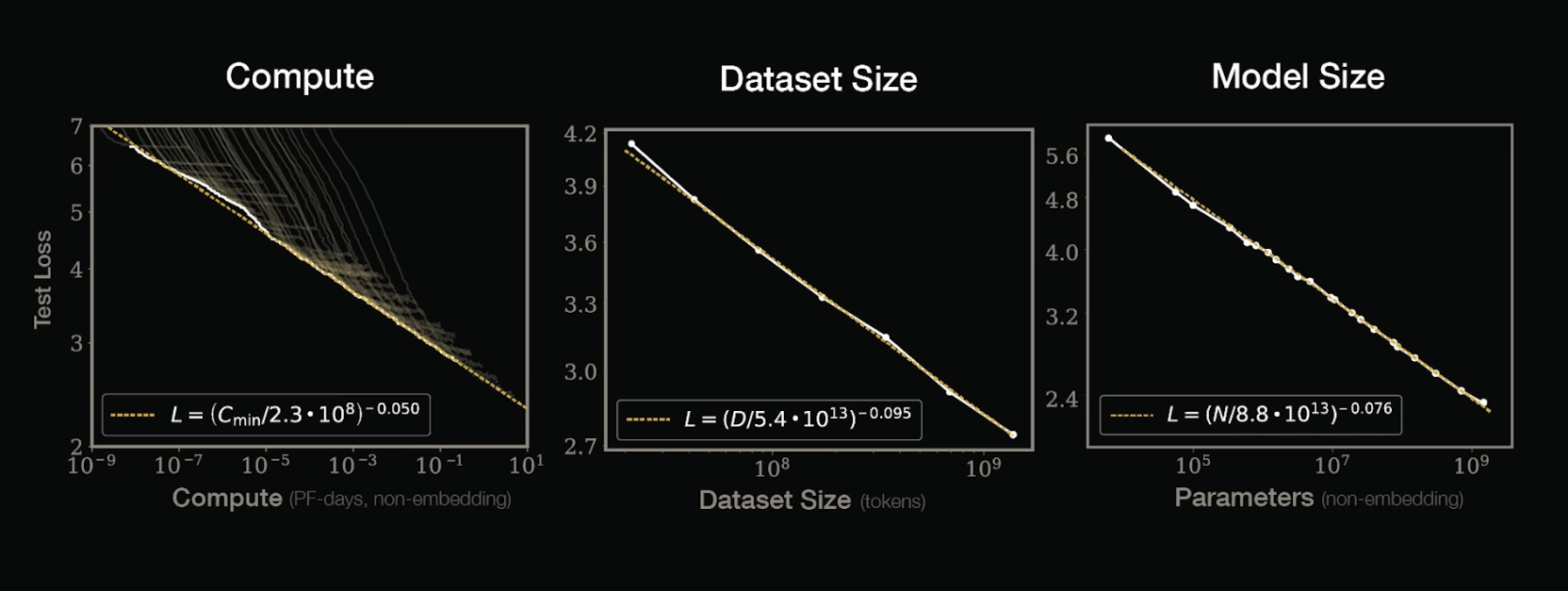
We’ve run out of data.
The largest models are already using all the text ever written. This paper [6] actually suggests that we’d need an exponential increases to the amount of data in the entire world just to maintain linear performance growth in native/zero-shot LLM capabilities and likely an entire universe’s worth of data to get to Artificial General Intelligence (AGI).
We’ve run out of size.
The version of Llama that I run locally has 7B parameters. GPT2 had 1.5B, GPT3 175B, and GPT4 topped 1.5T parameters. While we could theoretically always make the number go up, there’s a relation between model size and hardware requirements. And the biggest models aren’t often that much better than the smaller ones and are much cheaper to run. So, while bigger might be marginally better, bigger is also more expensive and slower.
The cost of adding compute to yield marginally better results is also failing on a cost/benefit analysis. Even the comparatively thrifty DeepSeek R1 still costs $60-100k per month to host and run yourself. More money will get faster results, but not better ones.
Second, LLMs - by their very nature - can’t be optimized to perfection.
To explain that, we’re going to have to do a little bit of math and talk about sandwiches.
The Mathematics of Loss
Despite all their magic, LLMs perform a very specific function which we can describe as, “Given the previous tokens, predict the next best token.”
There’s system prompts and user provided context and some bespoke training in there, but at the end of the day, 1.5T parameters and hundreds of GPUs are chained together to predict the next token until the next best token is an End of Sequence indicator.
LLMs do so by using a function called Softmax [7] . Softmax can also be described as “Given all of the possible outputs, normalize each individual output’s probability of being right so that all possible probabilities add up to 1” 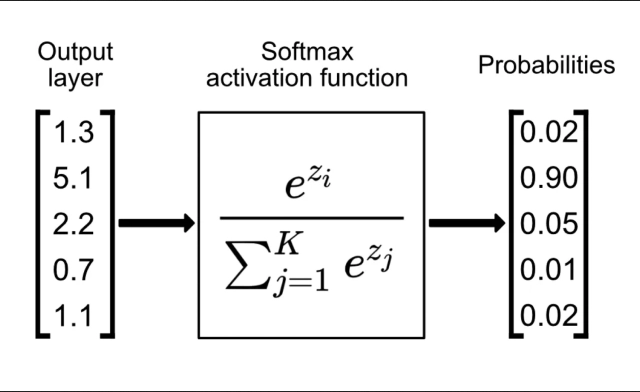
The above example has only 5 potential outputs, and when normalized, the second output will be chosen because of all the possible choices, option 2 has a 90% probability of being the correct output.
In machine learning, a loss can be (dramatic oversimplification) be written as
In the above example, the model has a loss of 1 - .9 = .1 or 10%
LLMs has far more than 5 potential outputs. OpenAI doesn’t publish how large their token vocabulary is, but we can safely assume it’s in the tens of thousands if not in the hundreds.
Softmax isn’t the issue though.
The issue is that LLMs are models of language and not models of knowledge. Language does not (and cannot) have a 100% correct next best token. It has many that are wrong, but also several that are probably correct. Language grows and evolves and morphs. It’s why a class of 30 kids write 30 different essays with the exact same thesis.
Which brings us to the sandwiches.
Let’s the the phrase “We finish each other’s ___” and imagine it as the input into an LLM with the task of predicting the next best token.
The two most popular tokens are:
- Sentences
- Sandwiches [+]This joke is far older than I thought. Yes, it was used heavily in Disney’s 2013 film Frozen [1], but it was also used in a 2005 episode of the Simpsons [2] and and 2003 episode of Arrested Development [3]
That's how language works, it's a growing, shifting set of tools that we can use to articulate knowledge, but only in a representative fashion.
Language is not knowledge, it's a way to represent knowledge. And it requires context.
That even cliches lack of a single concrete answer means that LLMs can never be tuned to have zero loss. Or even a 10% loss. The best possible tuned LLM is probably in the realm of 20% loss, meaning 1 out of every 5 predicted tokens is statistically optimal, but potentially incorrect.
Because LLMs only select the statistically correct next best token, I modified Box’s aphorism [8] into the following:
An LLM on it’s own will never be a knowledge source. Due to the nature of language, a statistical next best token prediction machine will never achieve Artificial General Intelligence. Intelligence needs discrete answers, 2+2 needs to always be 4 and strawberry always needs to have 3 Rs.
This isn’t to say that world is hitting the Neural Scaling Wall and giving up. In fact, there’s no fewer than three new means which folks are using to put their thumb on the ‘some just happen to be correct’ side of the scale.
But this post is already getting long, so in the next few weeks I’ll write about agents, agentic Ai, new models, and how to make AI useful.